| 氏名 | 研究科・学部 | 専攻・学科 | 学年 |
|---|---|---|---|
| 榊原 颯 | デザイン工学部 | システムデザイン学科 | 4 |
|
|||
作品要旨
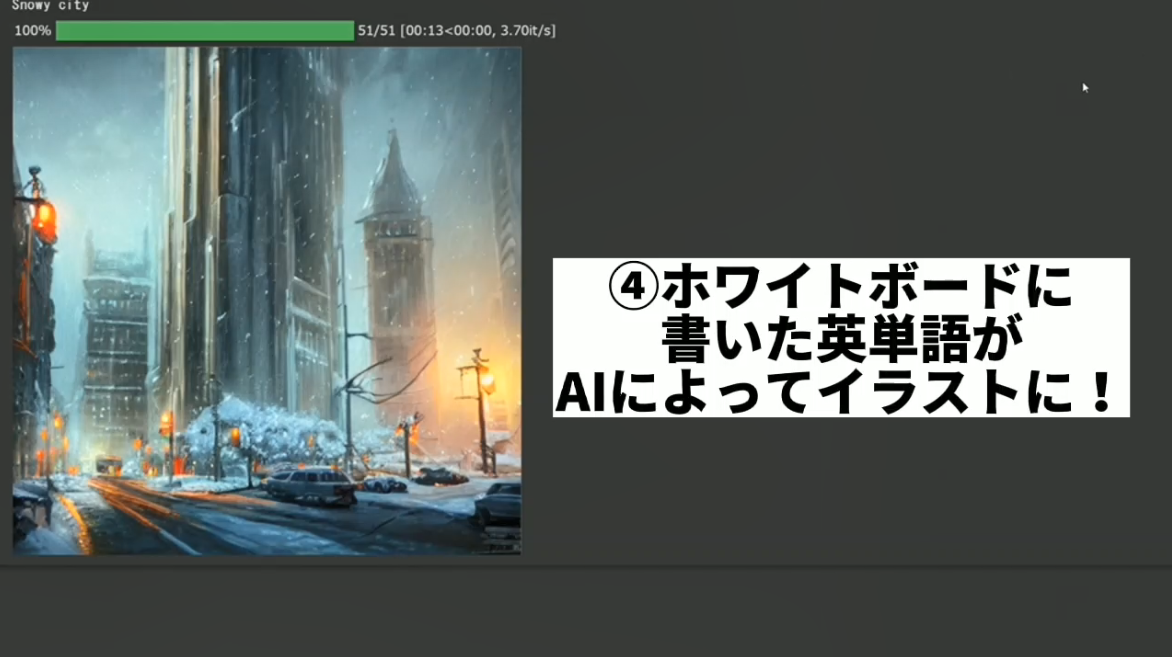
AIによるイラスト生成を、OCR(光学文字認識)を用いることでノートや黒板などのアナログ媒体を入力デバイスとして行えるコンテンツ。英語に触れたての児童にライティングを楽しんでもらうことを目的としている。
作品解説
2022年8月22日、汎用画像生成AIモデルStable Diffusionがオープンソースとして全世界に公開された。それから僅か1カ月余りしか経っていない2022年10月1日現在、画像生成AIは世界中の技術者達の手によってより高精度なものへ急速に進化する傍ら、経済的・倫理的問題からその是非の論争も激しさを増している。しかし、高精度な画像を利用して既存の産業を取って代わる事だけがこのAI技術の活かし方なのだろうか。このAIを使った時の「自分の指示でイラストが生成される」という最も原初的な喜び自体を何かに応用することはできないか。そう考え私は、自分の手書きした英語でイラストが生成されることで、英語にまだ馴染みの無い児童が英単語ライティングを楽しめるコンテンツを作成した。
光学文字認識を用いることで、黒板やノート等のアナログ媒体を、AIに命令するための入力デバイス化することに成功しており、PC1台あれば教室で児童でも皆でライティングによるイラスト生成を楽しむことができるようになっている。このコンテンツにより児童のライティングへの主体性や英語への想像力が養われることを目指す。
デジタル技術の使用箇所・方法
Pythonを用いて作成。Google Colaboratory環境で開発し、表示・動作もGoogle Colaboratory上で行う(処理の負荷の問題でGoogleのGPUを利用する必要があるため)。
使用した主な技術は大きく3つ
①OCR(光学文字認識)。手書きした英語を読み取るのに利用。
②AI画像生成。画像生成モデルStable Diffusionを活用。
③これら二つのシステムを統合しコンテンツとして動作可能にするプログラム。